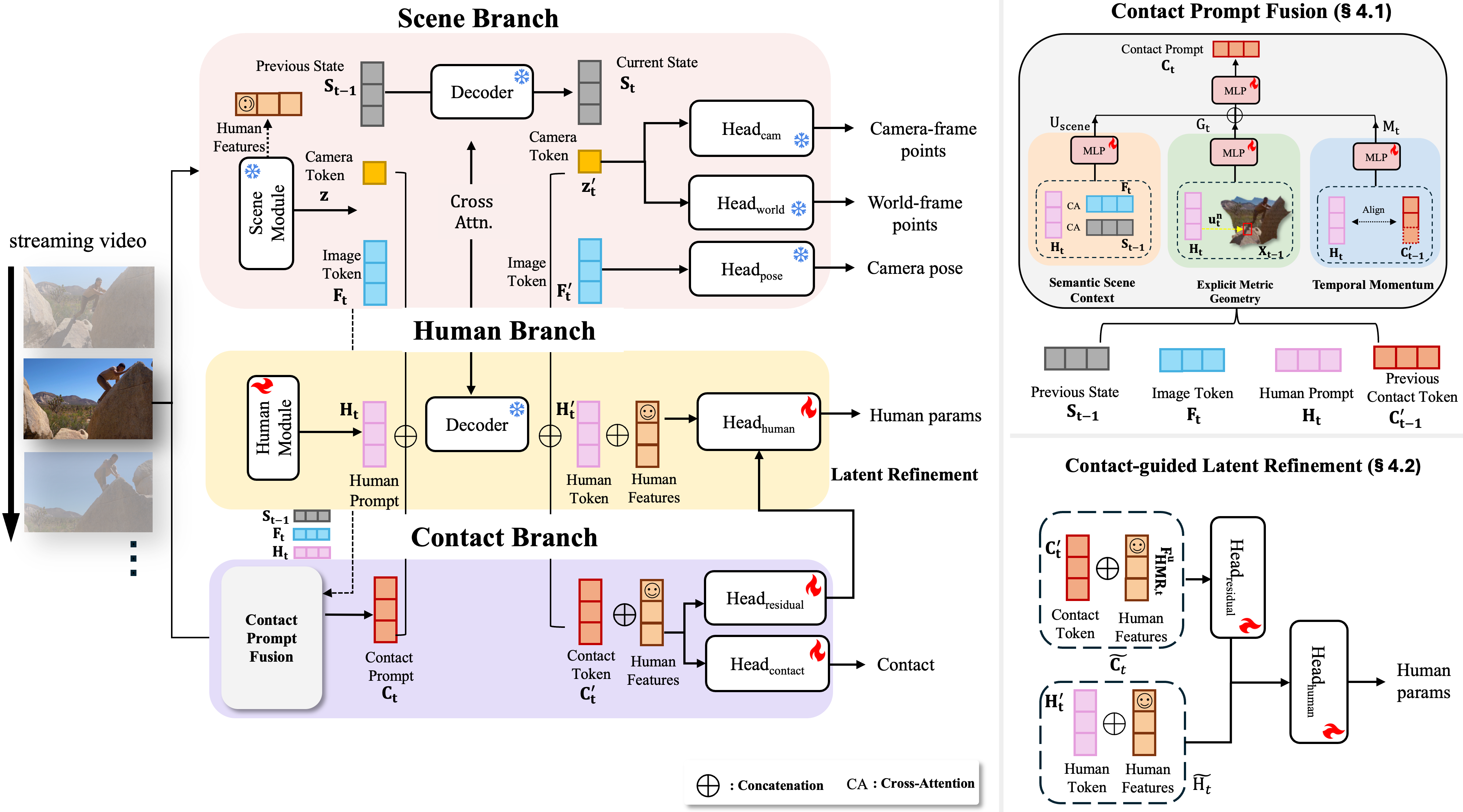
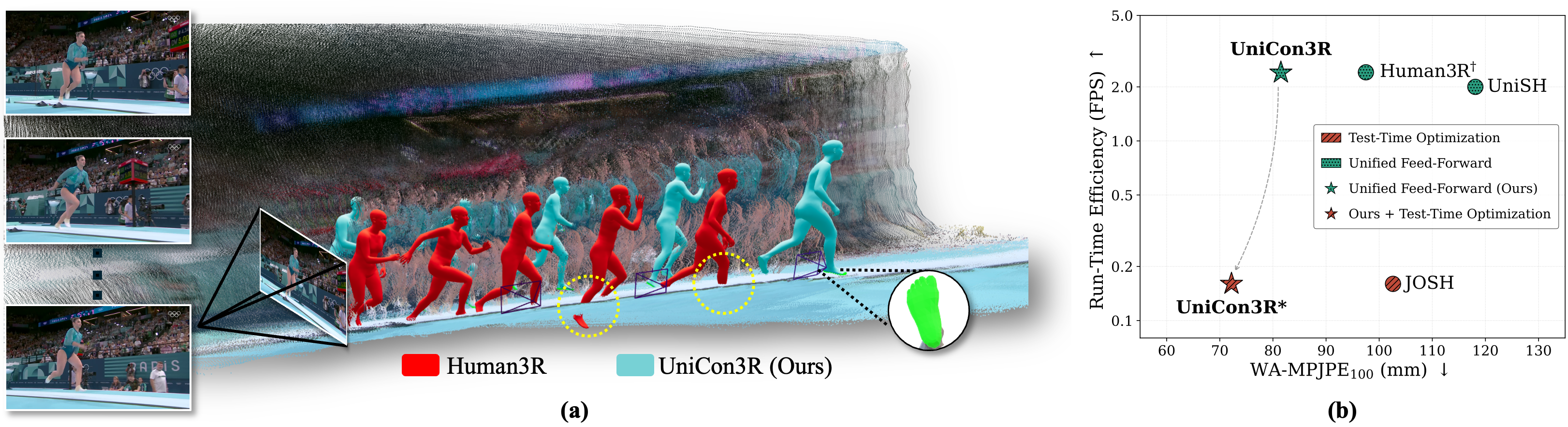
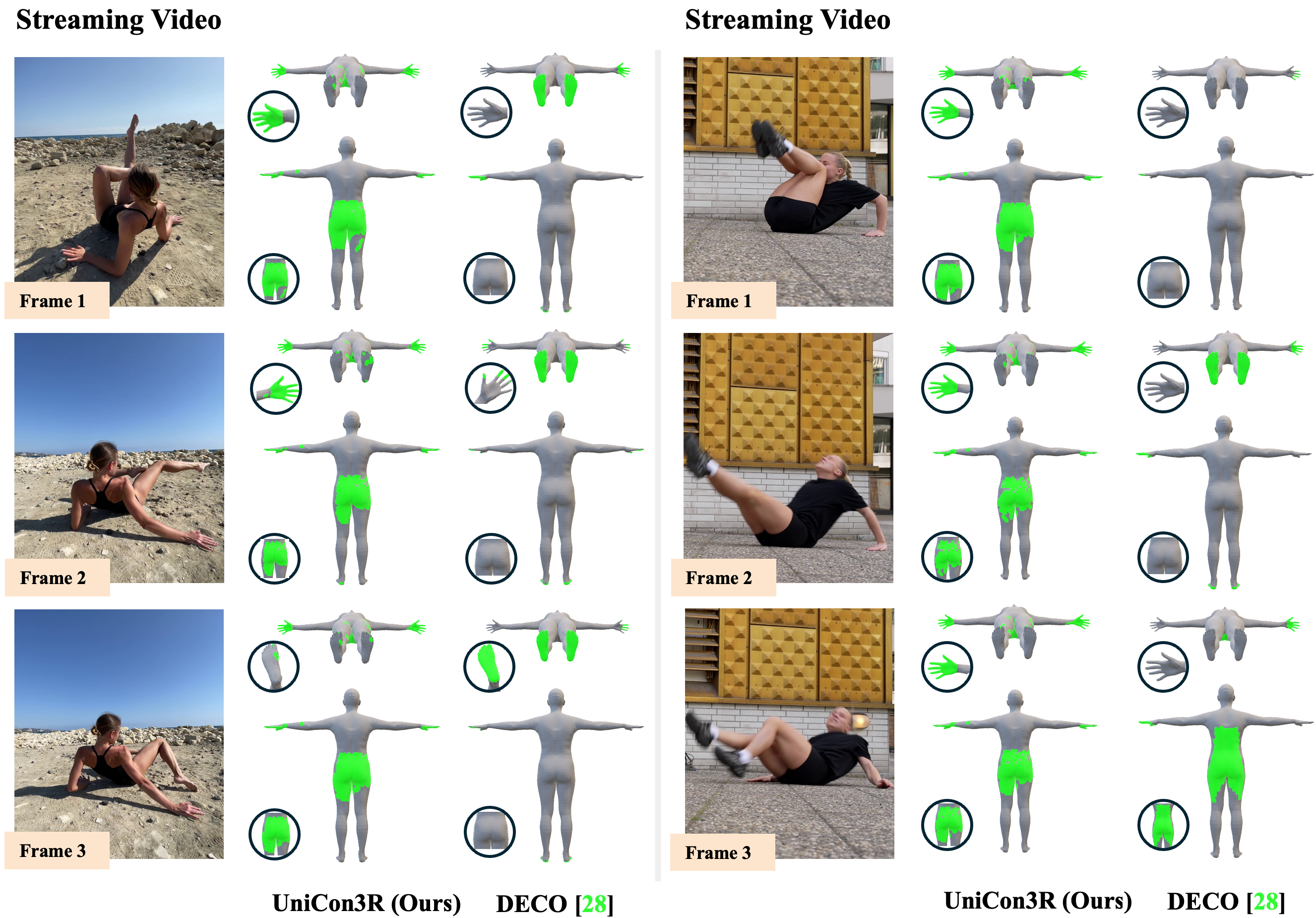
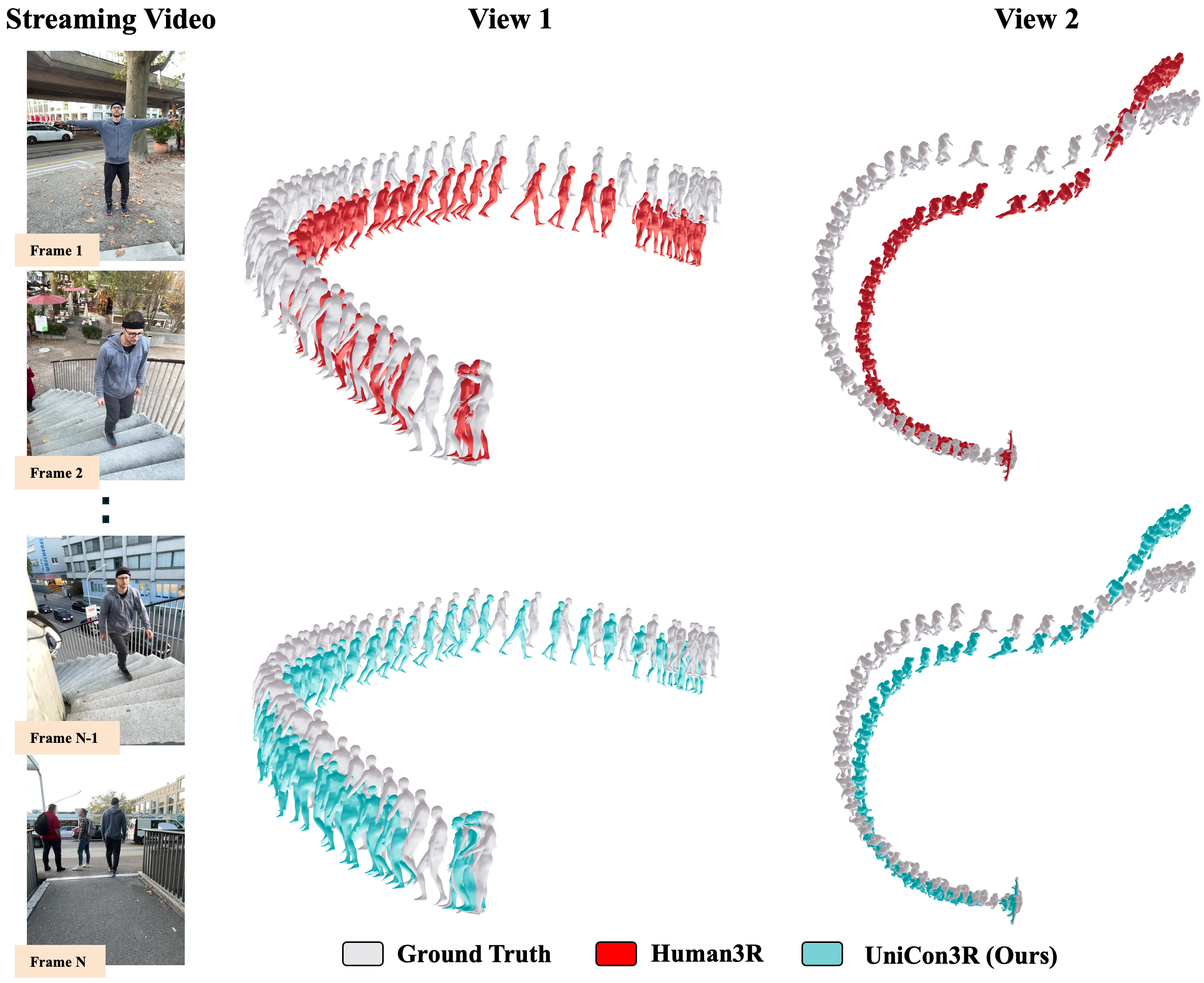
Interactive 4D Visualization
Explore the 4D reconstruction results of UniCon3R on various dynamic scenes. Use the controls below to orbit the scene, zoom, and fly through the reconstruction.
Moving forward and backward
Moving left and right
Moving upward and downward